
Continuous integration and continuous delivery for HPC
Will those binaries actually work? This is a central question for HPC practitioners and one that’s sometimes hard to answer: increasingly complex software stacks being deployed, and often on a variety of clusters. Will that program pick the right libraries? Will it perform well? With each cluster having its own hardware characteristics, portability is often considered unachievable. As a result, HPC practitioners rarely take advantage of continuous integration and continuous delivery (CI/CD): building software locally on the cluster is common, and software validation is often a costly manual process that has to be repeated on each cluster.
We discussed before that use of pre-built binaries is not inherently an obstacle to performance, be it for networking or for code—a property often referred to as performance portability. Thanks to performance portability, continuous delivery is an option in HPC. In this article, we show how Guix users and system administrators have benefited from continuous integration and continuous delivery on HPC clusters.
Hermetic builds
But first things first: before we talk about continuous integration, we need to talk about hermetic or isolated builds. One of the key insights of the pioneering work of Eelco Dolstra on the Nix package manager is this: by building software in isolated environments, we can eliminate interference with the rest of the system and practically achieve reproducible builds. Simply put, if Alice runs a build process in an isolated environment on a supercomputer, and Bob runs the same build process in an isolated environment on their laptop, they’ll get the same output (unless of course the build process is not deterministic).
From that perspective, pre-built binaries in Guix (and Nix) are merely substitutes for local builds: you can choose to build things locally, but as an optimization you may just as well fetch the build result from someone you trust—since it’s the same as what you’d get anyway.
A closely related property is full control of the software package
dependency graph. Guix package definitions stand alone: they can only
refer to one another and cannot refer to software that happens to be
available on the machine in /usr/lib64, say—that directory is not even
visible in the isolated build environment! Thus, a package in Guix has
its dependencies fully specified, down to the C library—and even
further
down.
Thanks to hermetic builds and standalone dependency graphs, sharing binaries is safe: by shipping the package and all its dependencies, without making any assumptions on software already available on the cluster, you control what you’re going to run.
Continuous integration & continuous delivery
Guix uses continuous integration to build its more than 22,000 packages
on several architectures: x86_64, i686, AArch64, ARMv7, and POWER9. The
project has two independent build farms. The main one, known as
ci.guix.gnu.org, was generously donated by
the Max Delbrück Center for Molecular Medicine
(MDC) in Germany; it has more than twenty
64-core x86-64/i686 build machines and a dozen of build machines for the
remaining architectures.
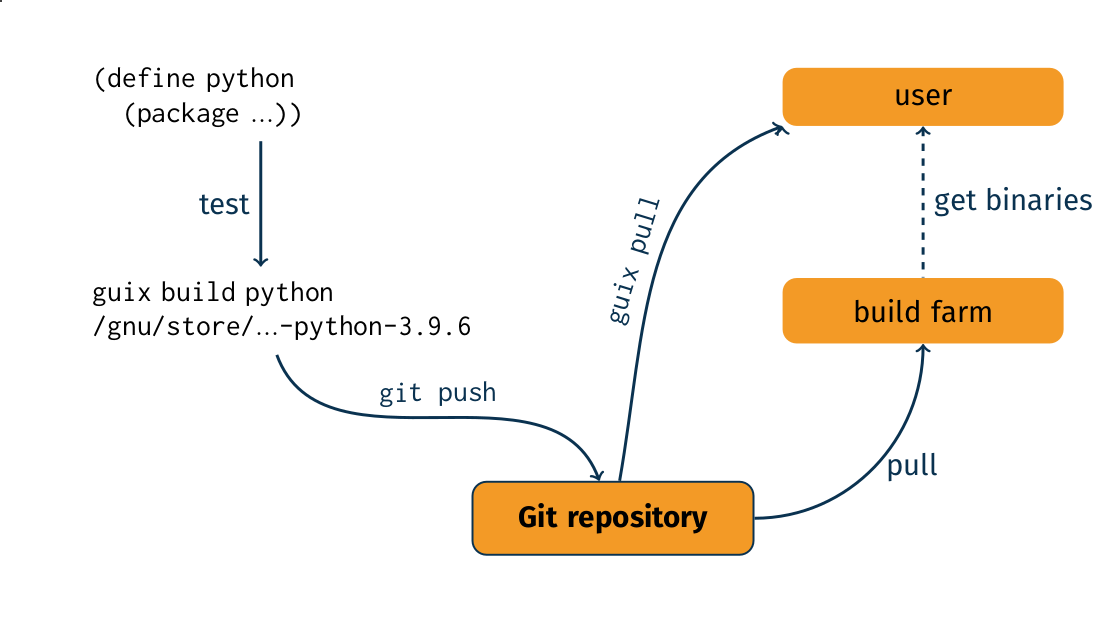
The diagram above illustrates the packaging workflow in Guix, which can be summarized as follows:
- packagers write a package definition;
- they test it locally by using
guix build; - eventually someone with commit access pushes the changes to the Git repository;
- build farms pull from the repository and build the new package.
Build farms are a quality assurance tool for packagers. For instance,
ci.guix runs
Cuirass. The web interface often
surprises newcomers—it sure looks different from those of Jenkins or
GitLab-CI!—but the key part is that it provides a dashboard that one can
navigate to look for packages that fail to build, fetch build logs, and
so on.
A big difference with traditional continuous integration tools is that
build results from the build farm are not thrown away: by running guix publish
on the build farm, those binaries are made accessible to Guix users. Any
Guix user may add ci.guix.gnu.org to their list of substitute
URLs
and they will transparently get binaries from that server.
One can check whether pre-built binaries of specific packages are
available on substitute servers by running guix weather:
$ guix weather gromacs petsc scotch
computing 3 package derivations for x86_64-linux...
looking for 5 store items on https://ci.guix.gnu.org...
https://ci.guix.gnu.org ☀
100.0% substitutes available (5 out of 5)
at least 41.5 MiB of nars (compressed)
109.6 MiB on disk (uncompressed)
0.112 seconds per request (0.2 seconds in total)
8.9 requests per second
looking for 5 store items on https://bordeaux.guix.gnu.org...
https://bordeaux.guix.gnu.org ☀
100.0% substitutes available (5 out of 5)
at least 30.0 MiB of nars (compressed)
109.6 MiB on disk (uncompressed)
0.051 seconds per request (0.2 seconds in total)
19.7 requests per secondThat way, one can immediately tell whether deployment will be quick or whether they’ll have to wait for compilation to complete…
Publishing binaries for third-party channels
Our research institutes typically have channels providing packages for their own software or software related to their field. How can they benefit from continuous integration and continuous delivery?
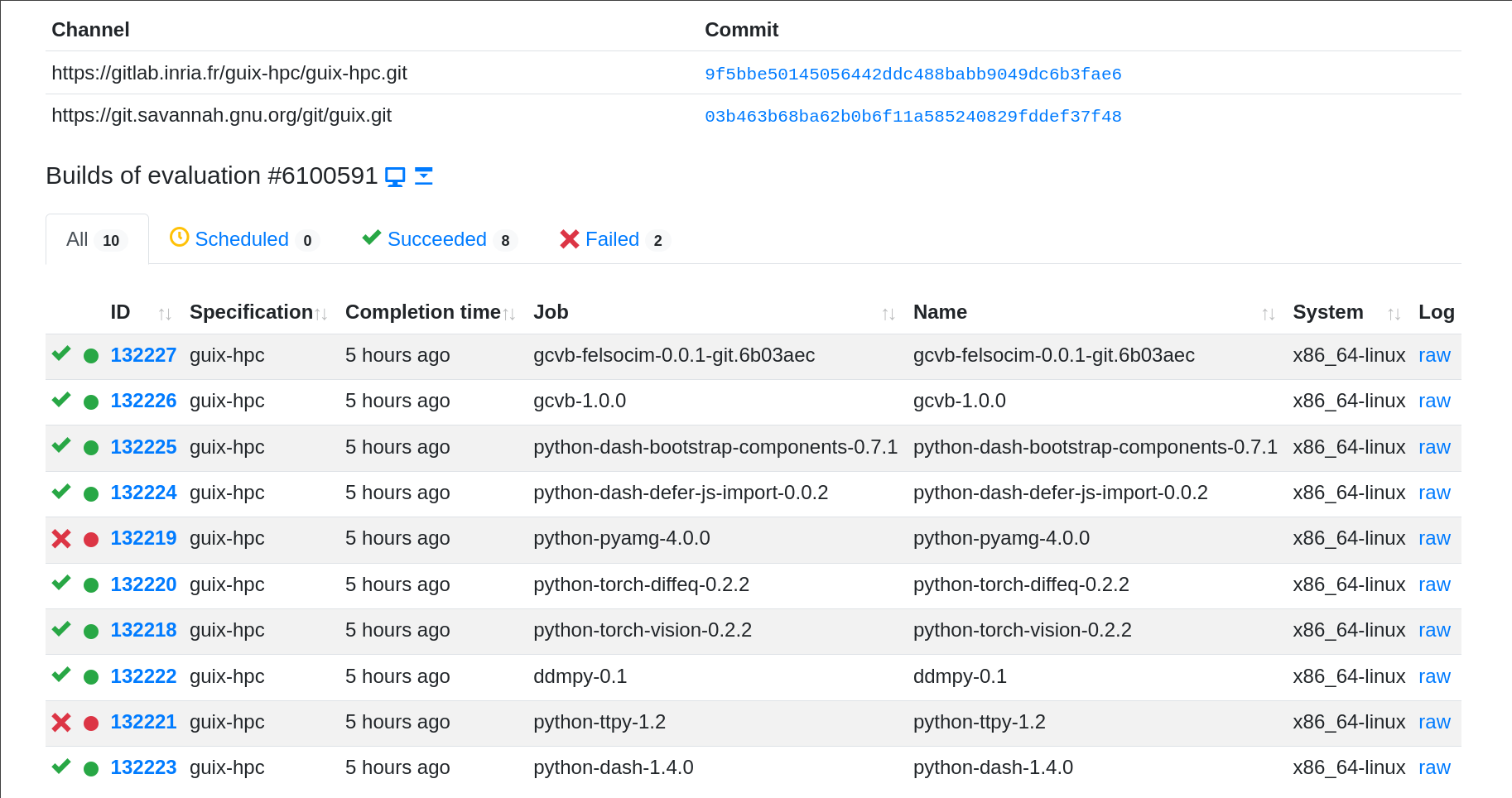
At Inria, we set up a build farm that
runs Cuirass and publishes its binaries with guix publish. Cuirass is
configured to build the packages of selected channels such as
guix-hpc and
guix-science (the Guix
manual
explains
how to set up Cuirass on Guix System; you can also check out the
configuration
of this build farm for details). That way, it complements the official
build farms of the Guix project.
The HPC clusters that the teams at Inria use, in particular
PlaFRIM and Grid’5000, are
set up to fetch substitutes from https://guix.bordeaux.inria.fr in
addition to the Guix’s default substitute servers. When deploying
packages from our channels on one of these clusters, binaries are
readily available—a significant productivity boost! That also applies
to binaries tuned for a specific CPU
micro-architecture.
The Grid’5000 setup takes advantage of this flexibility in interesting
ways. Grid’5000 is a “cluster of clusters” with 8 sites, each of which
has its own Guix installation. To share binaries among sites, each site
runs a guix publish instance, and each site has the other sites in its
list of substitute URLs. That way, if a site has already built, say,
Open MPI, the other sites will transparently fetch Open MPI binaries
from it instead of rebuilding it.
While Cuirass is a fine continuous integration tool tightly integrated with Guix, it’s also entirely possible to use one of the mainstream tools instead. Here are examples of computing infrastructure that publishes pre-built binaries:
- GliCID, the Tier-2 cluster for the region of Nantes (France), builds packages with Cuirass and publishes binaries.
- ZPID publishes binaries of relevant packages built with a simple cron script.
- GeneNetwork runs continuous integration jobs with Laminar and publishes the resulting binaries.
- Phil Beadling of Quantile Technologies explained how they integrated Guix in their Jenkins CI/CD pipeline.
As you can see, there’s a whole gamut of possibilities, ranging from the
“low-tech” setup to the fully-featured CI/CD pipeline. In all of these,
guix publish takes care of the publication part. If your focus is on
delivering binaries for a small set of packages, a periodic cron job as
shown above is good enough. If you’re dealing with a large package set
and are also interested in quality assurance, a tool like Cuirass may be
more appropriate.
Wrapping up
We computer users all too often work in silos. Developers might have their own build and deployment machinery that they use for continuous integration (GitLab-CI with some custom Docker image?); system administrators might deploy software on clusters in their own way (Singularity image? environment modules?); and users might end up running yet other binaries (locally built? custom-made?). We got used to it, but if we take a step back, it looks like this is one and the same activity with a different cloak depending on who you’re talking to.
Guix provides a unified approach to software deployment; building, deploying, publishing binaries, and even building container images all build upon the same fundamental mechanisms. We have seen in this blog post that this makes it easy to continuously build and publish package binaries. The productivity boost is twofold: local recompilation goes away, and site-specific software validation is reduced to its minimum.
For HPC practitioners and hardware vendors, this is a game changer.
Acknowledgments
Thanks to Lars-Dominik Braun, Simon Tournier, and Ricardo Wurmus for their insightful comments on an earlier draft of this post.
Unless otherwise stated, blog posts on this site are copyrighted by their respective authors and published under the terms of the CC-BY-SA 4.0 license and those of the GNU Free Documentation License (version 1.3 or later, with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts).



