
Tuning packages for a CPU micro-architecture
It should come as no surprise that the execution speed of programs is a primary concern in high-performance computing (HPC). Many HPC practitioners would tell you that, among their top concerns, is the performance of high-speed networks used by the Message Passing Interface (MPI) and use of the latest vectorization extensions of modern CPUs.
This post focuses on the latter: tuning code for specific CPU micro-architectures, to reap the benefits of modern CPUs, with the introduction of a new tuning option in Guix. But first, let us consider this central question in the HPC and scientific community: can “reproducibility” be achieved without sacrificing performance? Our answer is a resounding “yes”, but that deserves clarifications.
Reproducibility & high performance
The author remembers advice heard at the beginning of their career in HPC—advice still given today—: that to get optimal MPI performance, you would have to use the vendor-provided MPI library; that to get your code to perform well on this new cluster, you would have to recompile the complete software stack locally; that using generic, pre-built binaries from a GNU/Linux distribution just won’t give you good performance.
From a software engineering viewpoint, this looks like a sad situation and an inefficient approach, dismissing the benefits of automated software deployment as pioneered by Debian, Red Hat, and others in the 90’s or, more recently, as popularized with container images. It also means doing away with reproducibility, where “reproducibility” is to be understood in two different ways: first as the ability to re-deploy the same software stack on another machine or at a different point in time, and second as the ability to verify that binaries being run match the source code—the latter is what reproducible builds are concerned with.
But does it really have to be this way? Engineering efforts to support performance portability suggest otherwise. We saw earlier that an MPI implementation like Open MPI, today, does achieve performance portability—that it takes advantage of the high-speed networking hardware at run-time without requiring recompilation.
Likewise, in a 2018 article, we looked at how generic, pre-built binaries can and indeed often do take advantage of modern CPUs by selecting at run-time the most efficient implementation of performance-sensitive routines for the host CPU. The article also highlighted cases where this is not the case; these are those we will focus on here.
The jungle of SIMD extensions
While major CPU architectures such as x86_64, AArch64, and POWER9 were defined years ago, CPU vendors regularly extend them. Extensions that matter most in HPC are vector extensions: single instruction/multiple data instructions and registers. In this area, a lot has happened on x86_64 CPUs since the baseline instruction set architecture (ISA) was defined. As shown in the diagram below, Intel and AMD have been tacking ever more powerful SIMD extensions to their CPUs over the years, from SSE3 to AVX-512, leading to a wealth of CPU “micro-architectures”.
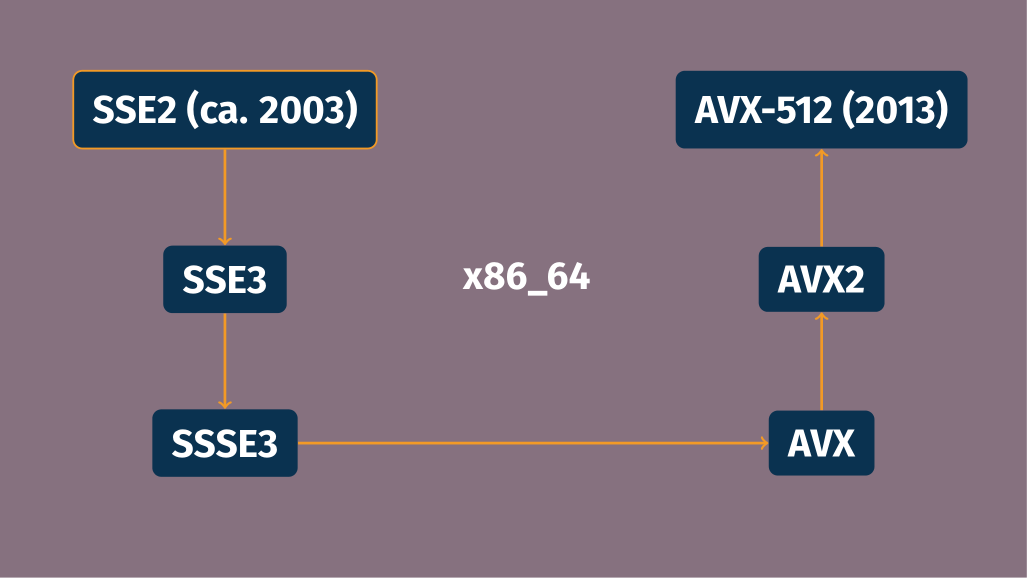
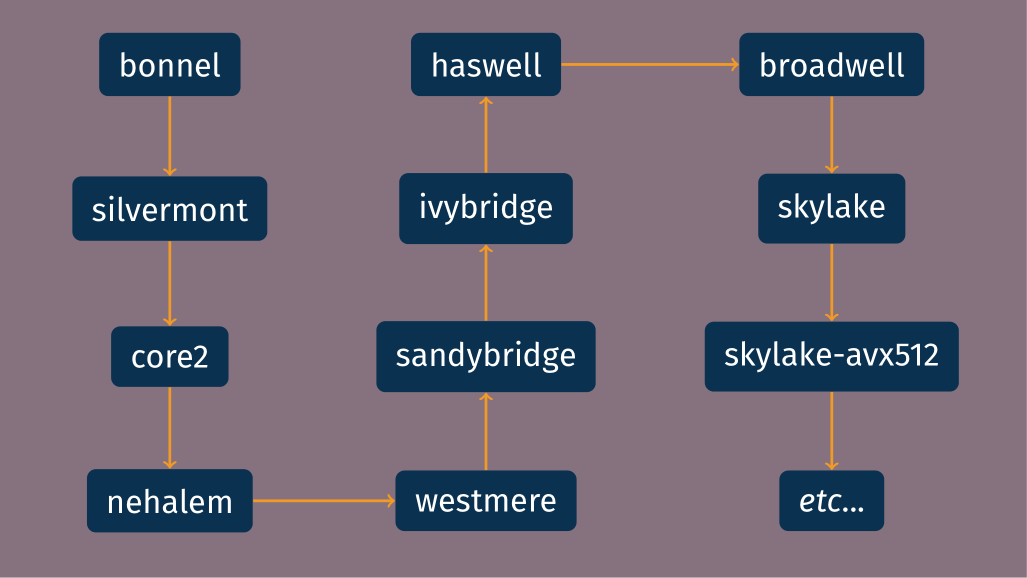
This gives a high-level view, but just looking at generations of Intel processors by their code name shows an already more complicated story:
Linear algebra routines that scientific software relies on greatly benefit from SIMD extensions. For example, on a modest Intel CORE i7 processor (of the Skylake generation, which supports AVX2), the AVX2-optimized version of the dense matrix multiplication routines of Eigen, built with GCC 10.3, peaks at ≅40 Gflops/s, compared to ≅11 Gflops/s for its baseline x86_64 version—four times faster!
When function multi-versioning isn’t enough
In our 2018 post, we contemplated function multi-versioning (FMV) as the solution to performance portability: the implementation provides multiple versions of “hot” routines, one for each relevant CPU micro-architecture, and picks the best one for the host CPU at run time. Many pieces of performance-critical software already use this technique; software that doesn’t do that yet can easily do so thanks to compiler toolchain support.
To make the case for FMV, we wanted to see what it would take us to actually add FMV support to code that would benefit from it. In the spirit of the Clear Linux automatic FMV patch generator, we wrote an automatic FMV tool for Guix: you would give it a package name, and it would:
Build the package with the
-fopt-info-veccompiler flag to gather information about vectorization opportunities and their source code location.Generate a patch that, for each C function with vectorization opportunities, adds the
target_cloneattribute to generate a couple of vectorized versions—generic, AVX2, and AVX-512.Build the package with this FMV patch.
The tool can successfully FMV-patch a variety of packages written in C, such as the GNU Scientific Library, which contains plain sequential implementations of a variety of math routines. It was an exciting engineering experiment… but we found it to be all too often inapplicable, for two reasons: performance-critical software already does FMV, or it’s not written in C.
We realized there’s a common pattern where FMV isn’t applicable, or at least isn’t applied: C++ header-only libraries. There’s no shortage of C++ header-only math libraries providing hand-optimized SIMD versions of their routines or otherwise supporting SIMD programming: Eigen, MIPP, xsimd and xtensor, SIMD Everywhere (SIMDe), Highway, and many more (C++ meta-programming for SIMD appears to be an attractive engineering effort). All these, except Highway, have in common that they do not support FMV and run-time implementation selection. Since they “just” provide headers, it is up to each package using them to figure out what to do in terms of performance portability.
In practice though, software using these C++ header-only libraries rarely makes provisions for performance portability. Thus, when compiling those packages for the baseline ISA, one misses out on all the vectorized implementations that libraries like Eigen provide. This is a known issue in search of a solution. It is a bit of a problem considering for instance the sheer number of packages depending on Eigen:

Fundamentally, run-time dispatch is at odds with the all-compile-time approach that header-only C++ template libraries are about. Furthermore, Eigen, for example, supports fine-grain vectorization; it may be used to operate on small matrices, as is common in computer graphics, and in that case inlining matrix operations is key to good performance—run-time dispatch would have to be done at a higher level.
Package multi-versioning
With our packaging hammer, one could envision a solution to these
problems: if we cannot do function multi-versioning, what about
implementing package multi-versioning? Guix makes it easy to define
package
variants,
so we can define package variants optimized for a specific CPU—compiled
with
-march=skylake,
for instance. What we need is to define those variants “on the fly”.
The new --tune package transformation
option,
which landed in Guix master a week ago, works along those lines.
Users can pass --tune to any of the command-line tools (guix install, guix shell, etc.) and that causes “tunable” packages to be
optimized for the host CPU. For example, here is how you would run
Eigen’s matrix multiplication
benchmark
from the
eigen-benchmarks
package, both with and without micro-architecture tuning:
$ guix shell eigen-benchmarks -- \
benchBlasGemm 240 240 240
240 x 240 x 240
cblas: 0.239963 (13.826 GFlops/s)
eigen : 0.267135 (12.419 GFlops/s)
l1: 32768
l2: 262144
$ guix shell --tune eigen-benchmarks -- \
benchBlasGemm 240 240 240
guix shell: tuning eigen-benchmarks@3.3.8 for CPU skylake
240 x 240 x 240
cblas: 0.208547 (15.908 GFlops/s)
eigen : 0.0720303 (46.06 GFlops/s)
l1: 32768
l2: 262144There are several things happening behind the scenes. First, --tune
determines the name of the host CPU as recognized by GCC’s (and Clang’s)
-march option; it does that using
code
inspired by that used by GCC’s
-march=native,
thought it’s currently limited to x86_64.
Users can also override auto-detection by passing a CPU name—e.g.,
--tune=skylake-avx512. However, the set of recognized CPU names varies
between GCC 11 and GCC 10, between GCC and Clang, and so on; passing the
wrong name to -march could result in obscure compilation errors. To
handle that gracefully, we instead add metadata to the compiler
packages
in Guix that lists the CPU names they know. This allows --tune to
emit a meaningful error when a CPU name unknown to the compiler is
given:
$ guix install eigen-benchmarks --tune=x86-64-v4
guix install: tuning eigen-benchmarks@3.3.8 for CPU x86-64-v4
The following package will be installed:
eigen-benchmarks 3.3.8
guix install: error: compiler gcc@10.3.0 does not support micro-architecture x86-64-v4As mentioned earlier, we made the conscious choice of letting --tune
operate solely on packages explicitly marked as “tunable”, which
packagers can do along these lines:
(define-public eigen-benchmarks
(package
(name "eigen-benchmarks")
;; …
(properties '((tunable? . #true)))))This is to ensure Guix does not end up rebuilding packages that could not possibly benefit from micro-architecture-specific optimizations, which would be a waste of resources. (For the same reason, we rejected the idea of defining separate system types for the various x86_64 CPU micro-architectures the way Nix 2.4 did.)
In the spirit of avoiding needless package rebuilds, --tune leverages
the “graft”
mechanism:
package variants are grafted to the dependency graph, such that
dependents of a tuned package do not need to be rebuilt. To illustrate
that, consider the figure below:
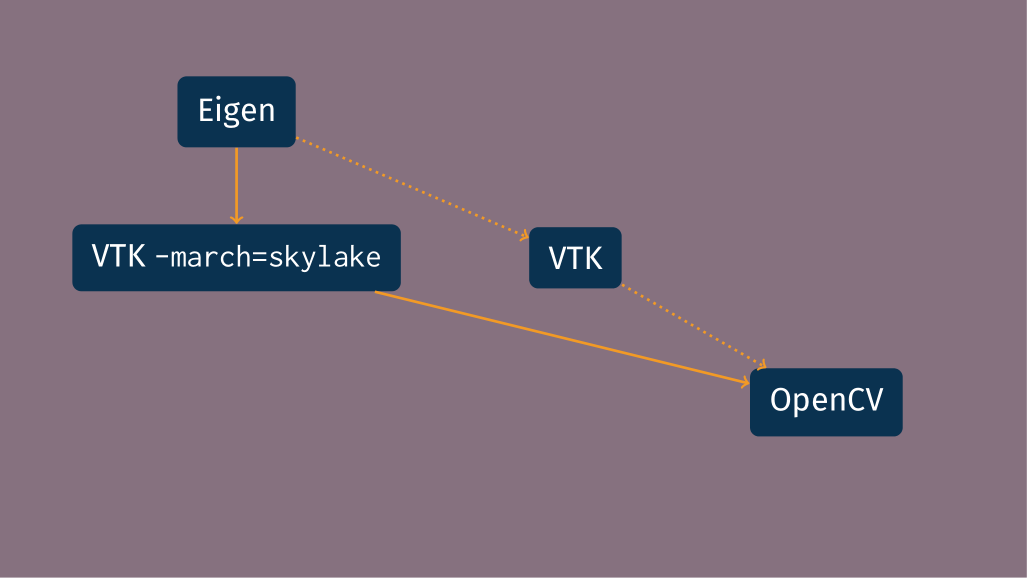
OpenCV depends on VTK, which depends on Eigen, as shown by the dotted
arrows. VTK is marked as tunable so it can benefit from SIMD
optimizations in Eigen. When --tune is passed, the optimized variant
of VTK built with -march=skylake is generated and grafted onto the
dependency graph, such that OpenCV itself does not need to be recompiled
and instead is relinked against the optimized VTK variant.
Importantly, this implementation of package multi-versioning does
not sacrifice reproducibility. When --tune is used, from Guix’s
viewpoint, it is just an alternate, but well-defined dependency graph
that gets built. Guix records package transformation options that were
used so it can “replay” them, for example by exporting a faithful
manifest:
$ guix shell eigen-benchmarks --tune
guix shell: tuning eigen-benchmarks@3.3.8 for CPU skylake
[env]$ guix package --export-manifest -p $GUIX_ENVIRONMENT
;; This "manifest" file can be passed to 'guix package -m' to reproduce
;; the content of your profile. This is "symbolic": it only specifies
;; package names. To reproduce the exact same profile, you also need to
;; capture the channels being used, as returned by "guix describe".
;; See the "Replicating Guix" section in the manual.
(use-modules (guix transformations))
(define transform1
(options->transformation '((tune . "skylake"))))
(packages->manifest
(list (transform1
(specification->package "eigen-benchmarks"))))The dependency graph resulting from tuning is recorded and can be
replayed—much unlike stealthily passing -march=native during a build.
Like other transformation options, --tune is accepted by all the
commands, so you could just as well build a Singularity image tuned for
a particular CPU:
guix pack -f squashfs -S /bin=bin \
eigen-benchmarks bash --tuneThis comes in handy if you want to prepare an image to run on another cluster, where you know you can rely on a given CPU extension.
The Guix build farm is set up to build a few optimized package
variants.
That way, users of --tune are likely to get substitutes (pre-built
binaries) even for the optimized variants, making deployment just as
fast as with non-tuned packages. To achieve this, --tune skips
running test suites when building packages: we cannot be sure that build
machines implement the CPU micro-architecture at hand.
Conclusion and outlook
We implemented what we call “package multi-versioning” for C/C++ software that
lacks function multi-versioning and run-time dispatch, a notable example
of which is optimized C++ header-only libraries. The new --tune
option is just one guix pull away; users and packagers can already
take advantage of it. It is another way to ensure that users do not
have to trade reproducibility for performance.
The scientific programming landscape has been evolving over the last few
years. It is encouraging to see that Julia
offers function multi-versioning for its “system
image”, and that,
similarly, Rust supports it with annotations similar to GCC’s
target_clones.
Hopefully these new development environments will support performance
portability well enough that users and packagers will not need to
worry about it.
Acknowledgments
Thanks to Ricardo Wurmus for insightful comments and suggestions on an earlier draft of this article.
Unless otherwise stated, blog posts on this site are copyrighted by their respective authors and published under the terms of the CC-BY-SA 4.0 license and those of the GNU Free Documentation License (version 1.3 or later, with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts).



